
계수 정렬이란?
- 특정한 조건이 부합할 때만 사용할 수 있지만 매우 빠르게 동작하는 정렬 알고리즘.
-> 데이터의 크기 범위가 제한되어 정수 형태로 표현할 수 있을 때 사용 가능하다.
-> 가장 큰 데이터와 가장 작은 데이터의 차이가 1,000,000을 넘지 않을 때 효과적으로 사용할 수 있다.
-> 동일한 데이터가 여러번 등장할 때 효과적.
- 각 인덱스에 해당하는 데이터가 몇 번 등장하는지 카운트해주면 됨.
- 데이터의 개수 N, 데이터(양수) 중 최댓값이 K일 때 최악의 경우에도 O(N + K)의 수행시간을 보장.
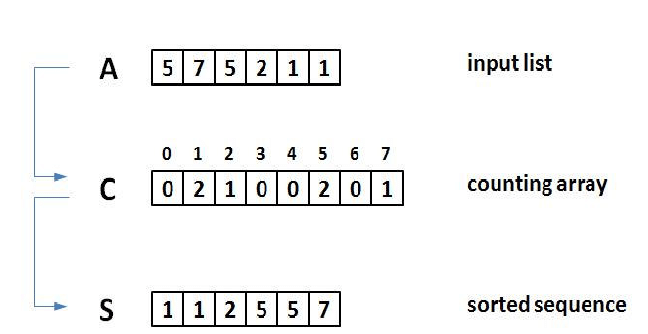
# 계수 정렬
# 모든 원소의 값이 0보다 크거나 같다고 가정
numbers = [3, 7, 1, 9, 11, 10, 5, 4, 2, 4, 5, 2, 8, 1, 5, 3]
# 모든 범위를 포함하는 리스트 선언(모든 값은 0으로 초기화)
count = [0] * (max(numbers) + 1)
# 각 숫자가 나올 때마다 카운트해줌.
for number in numbers:
count[number] += 1
# 각 인덱스를 카운트된 횟수만큼 출력
for i in range(len(count)):
for j in range(count[i]):
print(i, end=" ")'알고리즘 > 이론' 카테고리의 다른 글
| 이진 탐색(Binary Search) (0) | 2022.06.30 |
|---|---|
| 정렬 알고리즘 시간복잡도 비교 (0) | 2022.06.22 |
| 퀵 정렬(Quick Sort) (0) | 2022.06.22 |
| 삽입 정렬(Insertion Sort) (0) | 2022.06.22 |
| 선택 정렬(Selection Sort) (0) | 2022.06.22 |