
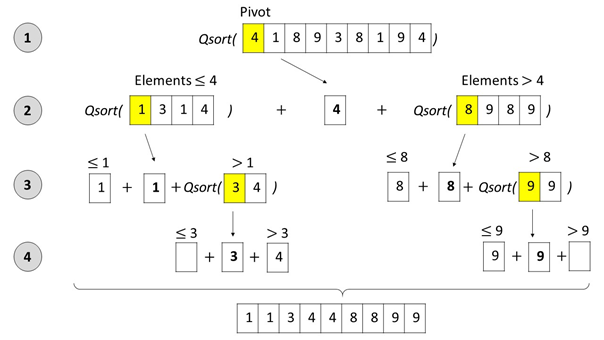
퀵 정렬이란?
- 기준 데이터를 설정하고 그 기준보다 큰 데이터와 작은 데이터의 위치를 바꾸는 방법.
- 일반적인 상황에서 가장 많이 사용되는 정렬 알고리즘 중 하나.
- 정렬 라이브러리의 근간이 되는 알고리즘이다.
- 가장 기본적인 퀵 정렬은 첫 번째 데이터를 기준 데이터(Pivot)으로 설정한다.
퀵 정렬의 시간 복잡도
- 퀵 정렬은 평균의 경우 O(NlogN)의 시간 복잡도를 가진다.
- 최악의 경우 O(N^2)의 시간 복잡도를 가진다.
-> 이미 정렬된 배열에 대해서 퀵 정렬을 수행할 경우 맨 왼쪽 원소가 자기 자신을 기준으로 나누기 때문이다.
-> 이 경우 한 원소 당 한번의 연산이 수행되는 꼴이므로 탐색O(N) * 나누기 N번 = O(N^2)이 나온다.
# 퀵 정렬
numbers = [3, 7, 1, 9, 11, 10, 5, 4, 2]
def quick_sort(array, start, end):
# 원소가 1개인 경우 종료
if start >= end:
return
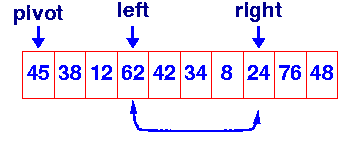
# 피벗은 1번째 원소(인덱스)
pivot = start
# 피벗 다음 요소부터라 start + 1(인덱스)
left = start + 1
right = end
# 두 뭉텅이로 나누어질 때까지 반복
while left <= right:
# 피벗보다 큰 데이터를 찾을 때까지 반복
# 끝에 도달하기전, 자신의 값이 피벗보다 아직 작을 때까지 이동.
while left <= end and array[left] <= array[pivot]:
left += 1
# 피벗보다 작은 데이터를 찾을 때까지 반복
while right > start and array[right] >= array[pivot]:
right -= 1
# 둘이 교차했을 경우, 작은 데이터(right)과 피벗 교체
if left > right:
array[pivot], array[right] = array[right], array[pivot]
# 교차하지 않았으면 서로(left, right)를 교체
else:
array[left], array[right] = array[right], array[left]
# 분할한 후 양 쪽에서 각각 정렬 수행 -> 재귀 활용
# 마지막에 pivot과 right의 위치가 바껴서 pivot대신 right을 기준으로 사용
quick_sort(array, start, right - 1)
quick_sort(array, right + 1, end)
quick_sort(numbers, 0, len(numbers) - 1)
print(numbers)# 퀵 정렬 업그레이드
numbers = [3, 7, 1, 9, 11, 10, 5, 4, 2]
def quick_sort(array):
# 리스트가 하나 이하의 원소를 담고 있다면 종료
if len(array) <= 1:
return array
# 피벗은 첫번째 원소
pivot = array[0]
# 피벗을 제외한 리스트
tail = array[1:]
# 피벗 제외 리스트에서 피벗보다 작거나 같은 수를 발견하면 저장
left_side = [x for x in tail if x <= pivot]
# 피벗 제외 리스트에서 피벗보다 큰 수를 발견하면 저장
right_side = [x for x in tail if x > pivot]
# 분할 이후 왼쪽 부분과 오른쪽 부분에서 각각 정렬 수행하고, 전체 리스트를 반환
return quick_sort(left_side) + [pivot] + quick_sort(right_side)
print(quick_sort(numbers))'알고리즘 > 이론' 카테고리의 다른 글
| 정렬 알고리즘 시간복잡도 비교 (0) | 2022.06.22 |
|---|---|
| 계수 정렬(Count Sort) (0) | 2022.06.22 |
| 삽입 정렬(Insertion Sort) (0) | 2022.06.22 |
| 선택 정렬(Selection Sort) (0) | 2022.06.22 |
| DFS(Depth First Search) & BFS(Breadth First Search) (0) | 2022.06.21 |